BGP Route Update Delay During HA Pair When Multiple BGP Peers Configured With Graceful restart Enabled
Symptom
-
Firewall in Active/Passive state running BGP for route forwarding with link path monitoring enabled.
-
Customer has graceful restart enabled for the BGP configurations on firewall.
-
Failing over the device to the Secondary firewall the BGP peer being established instantaneously
-
However, the route updates take over 45 - 180 seconds to be reflected on firewall.
-
Disabling graceful restart and failing over we could see that the process is much quicker on the firewall.
-
Viewing pcaps taken on the Firewall with graceful restart shows that the firewall takes 18 seconds to provide an update message.
-
But in pcaps without graceful restart the update message reply from firewall is instantaneous.
Environment
-
Palo Alto Firewall
-
HA Active/Passive
-
BGP peers configured with graceful restart enabled
Topology
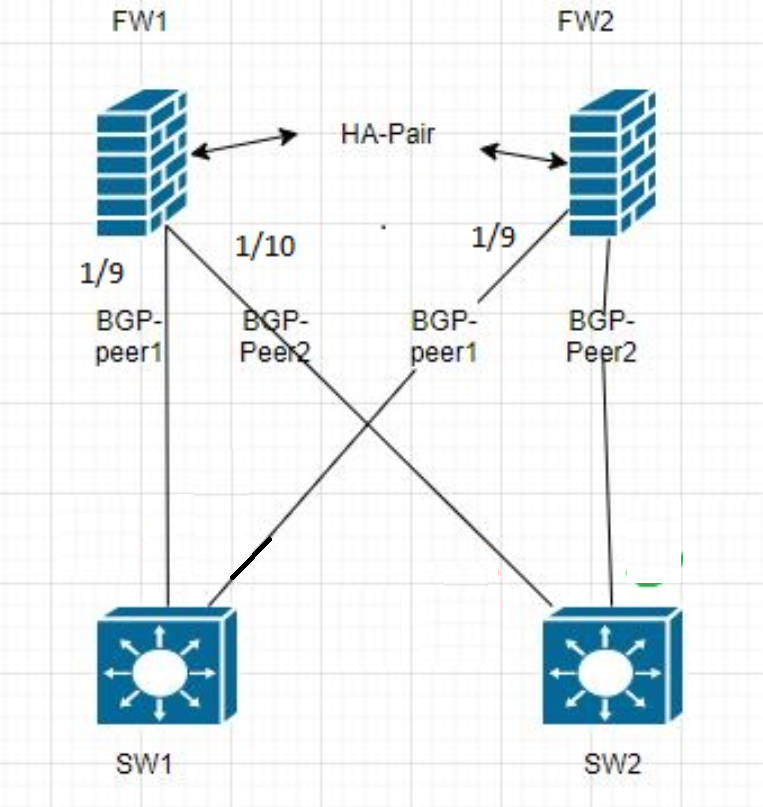
Cause
Explained in examples below.
Scenario 1
-
FW1 is active and it has BGP peering with SW1 and SW2.
-
When SW1 has both port down (simulated SW1 failure by a reboot ). For HA failover to take place SW2 port connected to FW1 was brought down.
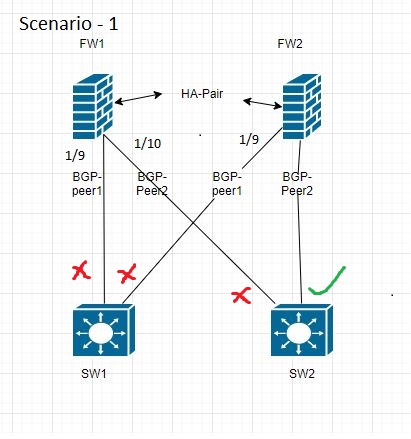
HA Link-monitor on FW1 detects both ports 1/9 and 1/10 down. It triggers fail-over.
BGP peering on FW2 on take-over initiates/receives BGP open from 1/10 will wait for link 1/9 up before it sends BGP update messages to all its peers( in this case 1/10 will wait unit 1/9 comes up). If port 1/9 dose not come up unit graceful restart time expire it will BGP update message to 1/10.
This is expected behavior. BGP waits for all its configured peers to be in open state before send update messages. Though this appears to be delay in route updates due to HA fail-over. This is a overlap of BGP convergence on a PA unit with HA fail-over and not a BGP update delay due to HA fail-over.
Scenario 2
-
If links on FW1 only fail. Upon takeover FW2 will have no issue reaching both peers and soon as both peers received BGP open message. Updates will be sent immediately.
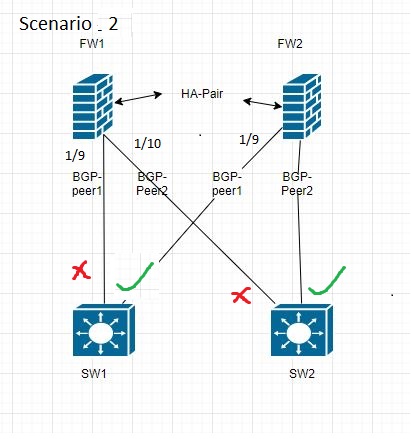
BGP waits for all its peers to be reachable before it sends update message. Once grace timer reaches. It ignores the unreachable peer and send updates to rest of the peers. This is to avoid excess update messages which consume more resource.
Resolution
-
This is expected behavior. BGP waits for all its configured peers to be in open state before send update messages.
-
Though this appears to be delay in route updates due to HA fail-over, This is a overlap of BGP convergence on a PA unit with HA fail-over and not a BGP update delay due to HA fail-over.
-
The Graceful restart timers can be adjusted (lowered) to reduce the time it takes for an update to be sent.
-
While lowering the graceful restart timers can speed up convergence in this scenario, how quickly the update can be sent is still reliant on the time it takes for BGP peering and RIB update to complete.