Introduction to Palo Alto Networks Path Monitoring
Palo Alto Networks firewalls offer a powerful feature called Path Monitoring , designed to enhance network resilience and reliability. This feature allows the firewall to actively verify the reachability of specific IP addresses, typically critical upstream devices like routers or servers, by sending ICMP pings. Based on the responsiveness of these monitored targets, the firewall can automatically take corrective actions to maintain connectivity, such as modifying routing tables or triggering High Availability (HA) failover.
Path Monitoring goes beyond simple interface link state (up/down) checks. While link monitoring confirms physical connectivity of an interface, path monitoring verifies the health of the *path* through that link to a downstream or upstream device. This is crucial because an interface link can be physically up, but connectivity beyond that link might be disrupted (e.g., an upstream router failure).
Understanding and effectively utilizing path monitoring is essential for network administrators aiming to build robust and fault-tolerant network infrastructures using Palo Alto Networks firewalls, and is a key topic for the PCNSE certification.
Core Concepts of Path Monitoring
Path Monitoring operates by sending probes, typically ICMP echo requests (pings), from a specified source interface/IP address on the firewall to one or more configured destination IP addresses. The reliability and responsiveness of these destination IPs are crucial; you should choose stable endpoints for monitoring.
How it Works:
- Probes: The firewall periodically sends ICMP pings to the monitored destination IP(s).
- Source IP: You must define the source IP address the firewall uses for these pings. This is typically an IP address configured on the egress interface for that path. For interfaces configured via DHCP, the firewall can use the dynamically assigned address.
-
Interval and Count:
You configure the frequency of these pings (
Interval) and the number of consecutive failed pings (CountorThreshold) that must occur before the path is considered down. Default values vary slightly depending on the context (Static Route, HA, PBF, Tunnel Monitoring) but generally involve sending pings every few seconds and requiring multiple failures before declaring the path down. -
Failure Condition:
When monitoring multiple destination IPs within a single group (e.g., for a static route or HA path group), you define a
Failure Condition.- Any: The path is considered down if *any* of the monitored destinations become unreachable. This is more sensitive to individual target failures.
- All: The path is considered down only if *all* monitored destinations become unreachable. This is more tolerant of single target failures, potentially useful if monitoring multiple diverse targets where one might go down for maintenance.
- Action on Failure: Depending on where path monitoring is configured (Static Route, PBF, HA, Tunnel), a failure triggers different actions, such as removing a static route, disabling a PBF rule, initiating HA failover, or disabling a tunnel interface.
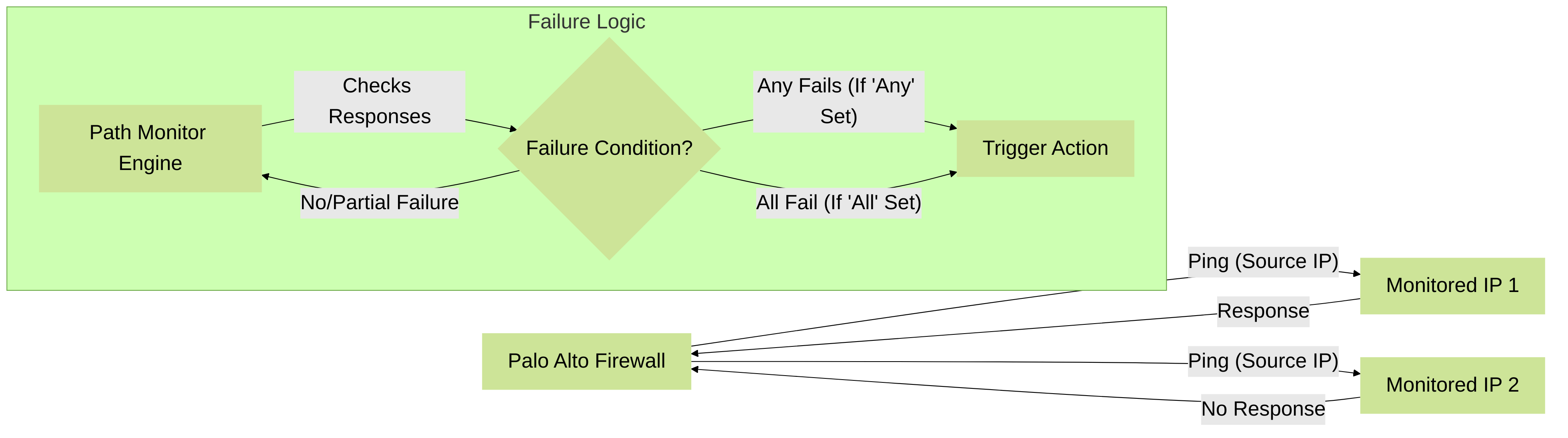
Conceptual flow of Path Monitoring probes and failure logic.
Use Case: Static Route Failover & Traffic Engineering
One of the primary use cases for Path Monitoring is to control the presence of static routes in the firewall's routing information base (RIB) and forwarding information base (FIB). This provides a mechanism for automatic failover between redundant paths, often used in dual-ISP scenarios.
Mechanism:
- Configuration: Path monitoring is enabled directly on a specific static route entry within a virtual router configuration. You define one or more destination IP addresses to monitor for that route.
- Monitoring: The firewall continuously sends ICMP pings from the configured source IP to the monitored destination(s) using the specified interval and count parameters.
- Failure Detection: If the monitored destination(s) become unreachable based on the `Failure Condition` (Any or All), the path monitoring state for that static route transitions to 'Down'.
- Route Removal: When the path monitor state is 'Down', the firewall removes the associated static route from the RIB and FIB.
- Failover: If a backup route (e.g., another static route with a higher metric, or a route learned via a dynamic routing protocol) exists for the same destination prefix, it will be installed in the FIB, redirecting traffic through the alternate path. This is analogous to Cisco's IP SLA with route tracking.
- Recovery and Preemption: When the monitored path recovers (destinations become reachable again), the path monitor state changes back to 'Up'. By default, there's a `Preemptive Hold Time` (default 2 minutes) during which the path must remain stable before the original static route is reinstalled into the RIB/FIB. Setting this timer to 0 allows immediate reinstallation. This prevents route flapping if the monitored path is unstable.
Scenario: Dual ISP Failover
An organization has two internet connections (ISP1 - primary, ISP2 - backup). Two default static routes (0.0.0.0/0) are configured:
- Route 1: Next hop via ISP1, Metric 10, Path Monitoring enabled (pinging ISP1 gateway and a reliable public IP like 8.8.8.8).
- Route 2: Next hop via ISP2, Metric 20, Path Monitoring disabled.
If the path monitoring for Route 1 fails (e.g., ISP1 gateway becomes unreachable), the firewall removes Route 1 from the FIB. Route 2, now having the best metric for 0.0.0.0/0, is installed, and traffic automatically fails over to ISP2. When ISP1's path recovers and the Preemptive Hold Time expires, Route 1 is reinstalled, becoming the active default route again.
Traffic Engineering Aspect:
While primarily for failover, this mechanism provides basic traffic engineering. By assigning lower metrics to preferred paths and enabling path monitoring, you ensure these paths are used only when healthy. If the preferred path degrades, traffic automatically shifts to a less preferred but currently functional path.
Use Case: Policy-Based Forwarding (PBF) Monitoring
Policy-Based Forwarding (PBF) allows administrators to override the firewall's route table and force specific traffic flows through a designated interface and next-hop gateway. Path Monitoring can be integrated with PBF rules to ensure the viability of the PBF path before forwarding traffic.
Mechanism:
-
Monitor Profile:
First, a Monitor Profile is created under Network > Network Profiles > Monitor. This profile defines the monitoring parameters:
- Action: What to do if the monitored target becomes unreachable. Options are typically `Wait Recover` or `Fail Over`.
- Interval: Frequency of ICMP probes (e.g., default 3 seconds).
- Threshold (Count): Number of consecutive failures before declaring the target unreachable (e.g., default 5).
-
PBF Rule Configuration:
The Monitor Profile is then applied to a PBF rule (Policies > Policy Based Forwarding). Within the PBF rule's 'Forwarding' tab, you specify:
- Egress Interface and Next Hop: The path the PBF rule enforces.
- Monitoring: Enable monitoring, select the created Monitor Profile, and specify the `IP Address` to ping for verifying the PBF path's health. This IP should be reachable via the specified Egress Interface and Next Hop.
- Operation: The firewall uses the Monitor Profile settings to ping the specified IP address.
-
Action on Failure:
If the monitored IP becomes unreachable based on the profile's threshold:
- Wait Recover: The PBF rule remains active, but traffic matching the rule might be dropped if the path is truly down. The firewall continues using the specified egress interface. This might be used if no backup path exists or if temporary drops are acceptable.
- Fail Over: The firewall effectively disables the PBF rule. Traffic matching the source/destination/application criteria of the disabled PBF rule will then fall back to the standard routing table lookup in the virtual router to determine the path. If a backup route (e.g., floating static route, dynamic route) exists, traffic can fail over.
- Recovery: When the monitored IP becomes reachable again, the PBF rule becomes fully active (if `Fail Over` was used) or simply confirms the path is healthy (if `Wait Recover` was used). PBF also supports an `Initial Hold Time` (optional, in Monitor Profile) to delay monitoring immediately after a PBF rule becomes active, and a `Hold Time` to wait after recovery before considering the path stable again.
Scenario: PBF for Specific Application Traffic with Failover
An organization wants all outbound Office 365 traffic from the Trust zone to use a dedicated ISP link (ISP1), while all other traffic uses a different link (ISP2 via default route). A PBF rule is created matching Office 365 applications from the Trust zone, forwarding traffic to ISP1's gateway via the ISP1 interface. A Monitor Profile with `Action: Fail Over` is applied, monitoring ISP1's gateway IP.
If ISP1's gateway becomes unresponsive, the PBF Monitor triggers the 'Fail Over' action, disabling the PBF rule. The Office 365 traffic no longer matches the (now disabled) PBF rule and falls back to the virtual router's routing table. If the default route points to ISP2, the Office 365 traffic fails over to ISP2 along with other general traffic. When the ISP1 gateway recovers, the monitor brings the PBF rule back online, and Office 365 traffic resumes using the dedicated ISP1 path.
Use Case: High Availability (HA) Link/Path Monitoring
In a High Availability (HA) Active/Passive pair, ensuring the active firewall has valid connectivity to critical network segments is essential for proper failover decisions. Palo Alto Networks provides both Link Monitoring and Path Monitoring specifically for HA.
- Link Monitoring: Checks the L1/L2 status (link up/down) of specified physical interfaces grouped into 'Link Groups'. Failover occurs if links within a group fail based on an 'Any' or 'All' condition for that group, and considering the overall 'Any' or 'All' condition for all configured link groups.
- Path Monitoring: Checks L3 reachability to specified IP addresses grouped into 'Path Groups'. Similar to link monitoring, failover is triggered based on 'Any' or 'All' conditions within a path group and considering the overall 'Any' or 'All' condition for all configured path groups. It uses ICMP pings to verify reachability.
Mechanism for HA Path Monitoring:
- Configuration: HA Path Monitoring is configured under Device > High Availability > Link and Path Monitoring > Path Monitoring.
- Path Groups: You create Path Groups, each containing one or more destination IP addresses to monitor. You also specify the ping interval and count (threshold) for determining reachability for the IPs within that group.
- Group Failure Condition: Within each Path Group, you set a `Failure Condition` (Any or All) to determine if the *group* is considered failed based on the reachability of the IPs it contains.
- Overall Failure Condition: At the main Path Monitoring level, you set an overall `Failure Condition` (Any or All) that determines if HA failover is triggered based on the status of all configured Path Groups. If set to 'Any', failure of *any* single Path Group (based on its internal condition) triggers HA failover. If set to 'All', *all* configured Path Groups must fail to trigger HA failover.
- Failover Trigger: If the path monitoring conditions are met (based on individual IP reachability, group conditions, and the overall condition), the active firewall determines it has lost critical connectivity and triggers a failover to the passive peer.
Scenario: Ensuring Upstream Router Availability
An HA pair sits between the internal network and two upstream routers (Router A and Router B) providing redundant internet paths. The administrator wants to ensure the active firewall fails over if it loses connectivity to *both* upstream routers.
Configuration:
- Create Path Group 1: Monitor Router A's IP. Failure Condition: Any (trivial as only one IP).
- Create Path Group 2: Monitor Router B's IP. Failure Condition: Any.
- Enable Path Monitoring overall. Set the overall Failure Condition to `All`.
Result: If the active firewall can ping Router A OR Router B, it remains active. Only if *both* Router A AND Router B become unreachable via ping from the active firewall will the Path Monitoring trigger an HA failover. This ensures failover only happens when complete upstream isolation is detected.
Configuration Locations & Key Parameters
Path monitoring configuration varies slightly depending on the use case. Here's a summary of locations and key parameters:
Configuration Locations:
- Static Route Path Monitoring: Network > Virtual Routers > (Select VR) > Static Routes > (Select Route) > Path Monitoring tab.
- PBF Path Monitoring: Requires a Monitor Profile (Network > Network Profiles > Monitor) applied within the PBF rule (Policies > Policy Based Forwarding > (Select Rule) > Forwarding tab).
- HA Path Monitoring: Device > High Availability > Link and Path Monitoring > Path Monitoring tab.
- Tunnel Monitoring: Requires a Monitor Profile (Network > Network Profiles > Monitor) applied within the IPSec Tunnel configuration (Network > IPSec Tunnels > (Select Tunnel) > Show Advanced Options).
Key Parameters:
| Parameter | Context | Description | Typical Range/Default | Reference |
|---|---|---|---|---|
| Destination IP / Monitored IP | Static Route, PBF, HA, Tunnel | The IP address(es) the firewall will ping to check reachability. Must be a reliable endpoint. | N/A (User Defined) | |
| Source IP | Static Route | The source IP address the firewall uses for ICMP pings. Typically an IP on the egress interface for the route. | Interface IP / DHCP Client Address | |
| Interval | Static Route, PBF, HA, Tunnel | The time (in seconds or milliseconds) between sending ICMP probes/pings. | Static: 1-60s (Def: 3s). HA: 200-60000ms (Def: 200ms). PBF/Tunnel (via Monitor Profile): 1-60s (Def: 3s). | |
| Count / Threshold | Static Route, PBF, HA, Tunnel | The number of consecutive missed probes/pings before declaring the destination/path down. | Static: 3-10 (Def: 5). HA: 3-10 (Def: 10). PBF/Tunnel (via Monitor Profile): 1-100 (Def: 5). | |
| Failure Condition | Static Route, HA | Determines if failure requires Any or All monitored destinations/groups to be unreachable. | Any / All (Default often 'Any') | |
| Preemptive Hold Time | Static Route | Minutes a recovered path must remain stable before the static route is reinstalled. 0 = immediate. | 0-1440 min (Def: 2 min) | |
| Action | PBF, Tunnel (via Monitor Profile) | Action to take upon failure: Wait Recover (keep using path) or Fail Over (disable PBF rule/tunnel interface). | Wait Recover / Fail Over | |
| Hold Time (Tunnel) | Tunnel (via Monitor Profile) | Time (in seconds) to wait after tunnel recovery before considering it stable and potentially reverting failover actions. | User Defined (e.g., part of profile) | (General concept, applied via profile) |
Tunnel Monitoring for IPSec VPNs
IPSec Tunnel Monitoring provides a mechanism specifically designed to verify connectivity *across* an established IPSec VPN tunnel, going beyond the basic IKE (Phase 1) and IPSec (Phase 2) SA status. It helps detect situations where the tunnel SAs might be up, but traffic cannot actually pass, or allows for faster failover detection than relying solely on Dead Peer Detection (DPD) in some scenarios.
While DPD checks the liveliness of the IKE SA (Phase 1 peer), it's often triggered only by Phase 2 rekey events on Palo Alto firewalls. Tunnel Monitoring provides a more active and direct way to test data plane connectivity through the tunnel.
Mechanism:
-
Monitor Profile:
Similar to PBF monitoring, Tunnel Monitoring uses a Monitor Profile (Network > Network Profiles > Monitor). This profile defines:
- Action: `Wait Recover` or `Fail Over`.
- Interval: Ping frequency (default 3 seconds).
- Threshold (Count): Number of missed pings before action (default 5).
- Tunnel Interface IP: The tunnel interface itself needs an IP address. This IP often serves as the source for the monitoring probes. Using private IPs like from the 169.254.0.0/16 range is common for tunnel interface addressing.
-
Tunnel Configuration:
Within the IPSec Tunnel configuration (Network > IPSec Tunnels > [Select Tunnel]), under 'Show Advanced Options':
- Enable `Tunnel Monitor`.
- Select the created `Monitor Profile`.
- Specify the `Destination IP` to ping. This is typically the IP address assigned to the *remote peer's* tunnel interface. Ensure this IP is reachable only through the tunnel and allowed by security policies.
- Operation: The firewall sends ICMP pings from the local tunnel interface IP to the specified remote Destination IP across the VPN tunnel at the configured interval.
-
Action on Failure:
- Wait Recover: The firewall considers the tunnel interface logically up for routing purposes, even if pings fail. It continues attempting to re-negotiate IPSec keys to accelerate recovery.
- Fail Over: The firewall disables the tunnel interface, removing associated routes from the routing table. This allows traffic to potentially reroute via a backup tunnel or path, if configured (e.g., using static routes with different metrics pointing to primary and secondary tunnel interfaces). The firewall still attempts to renegotiate keys for the failed tunnel.
- Recovery: When pings succeed again, the tunnel is considered recovered. If 'Fail Over' was used, the tunnel interface is re-enabled, and associated routes are potentially restored based on routing protocol logic or static route preemption timers.
- Tunnel Monitoring: Directly monitors reachability *through* the tunnel to the peer's tunnel interface IP. The action (`Wait Recover`/`Fail Over`) directly affects the tunnel interface state. Simpler for basic tunnel up/down detection.
- Static Route Path Monitoring: Monitors reachability to *any* IP (could be beyond the tunnel peer) via the route using the tunnel interface. Failure removes the static route, indirectly causing failover if a backup route exists. More flexible if you need to monitor reachability *beyond* the immediate tunnel peer.
PCNSE Path Monitoring Quiz
Test your understanding of Palo Alto Networks Path Monitoring concepts.
Conclusion
Palo Alto Networks Path Monitoring is a versatile and crucial feature for building resilient and reliable network infrastructures. By actively probing the reachability of critical network paths, it enables automated responses to failures that simple link-state monitoring cannot detect.
Key takeaways include:
- Static Route Failover: Provides robust automatic failover for redundant paths (like dual ISPs) by removing routes when paths become unhealthy.
- PBF Enhancement: Ensures Policy-Based Forwarding rules only direct traffic down viable paths, with options to disable the rule or wait for recovery upon failure.
- HA Trigger: Offers granular control over High Availability failover based on the L3 reachability of upstream devices or critical paths, complementing physical link monitoring.
- Tunnel Verification: Actively monitors connectivity across IPSec tunnels, providing faster and more reliable failure detection than DPD alone in many cases.
Understanding the nuances of configuration parameters like Interval, Count/Threshold, Failure Condition (Any/All), and specific actions (Preemption, Wait Recover, Fail Over) is essential for effective deployment and troubleshooting, and forms a core knowledge area for PCNSE certification candidates.
By leveraging Path Monitoring appropriately across static routes, PBF, HA, and VPN tunnels, administrators can significantly enhance network uptime and ensure seamless connectivity even in the face of upstream network issues.